DistributedDataParallel non-floating point dtype parameter with
4.7 (572) · $ 24.99 · In stock
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re
PyTorch Release v1.2.0
Finetune LLMs on your own consumer hardware using tools from PyTorch and Hugging Face ecosystem

4. Memory and Compute Optimizations - Generative AI on AWS [Book]
A comprehensive guide of Distributed Data Parallel (DDP), by François Porcher

images.contentstack.io/v3/assets/blt71da4c740e00fa

源码分析] Facebook如何训练超大模型---(4) - 罗西的思考- 博客园

How to train on multiple GPUs the Informer model for time series forecasting? - Accelerate - Hugging Face Forums
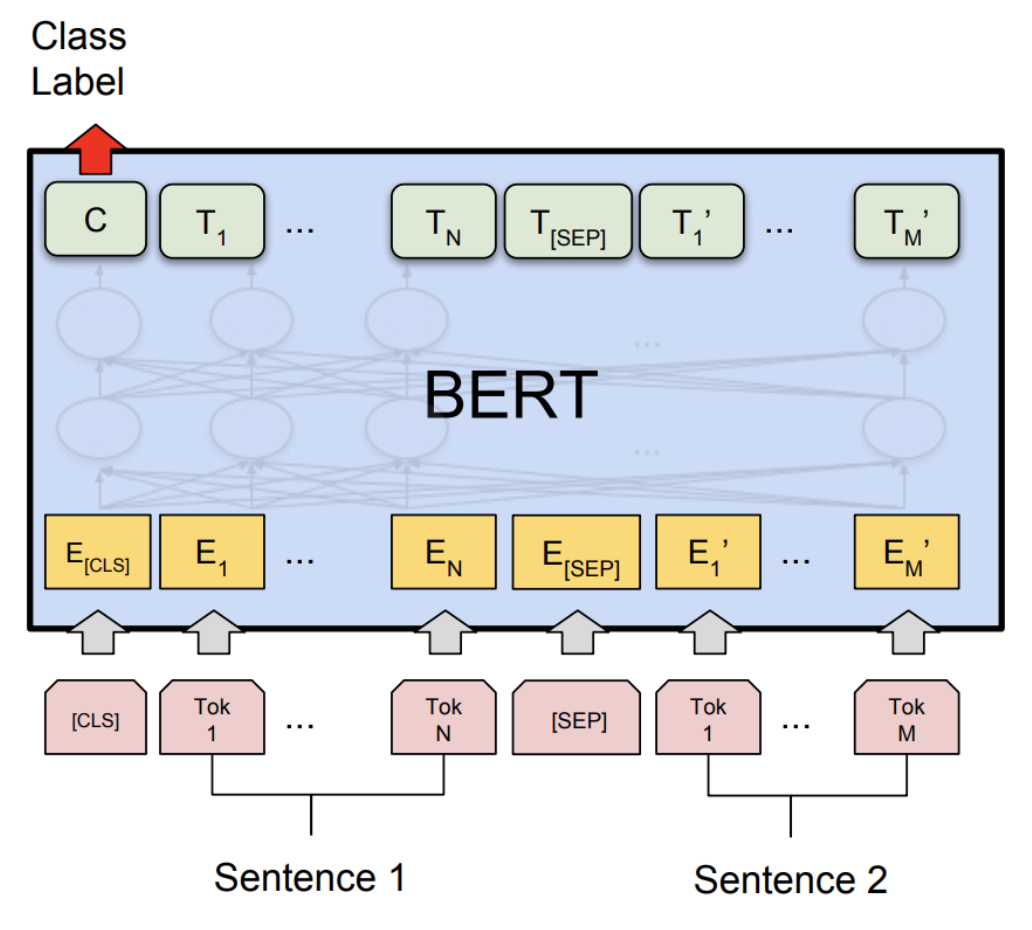
beta) Dynamic Quantization on BERT — PyTorch Tutorials 2.2.1+cu121 documentation

源码解析] 模型并行分布式训练Megatron (2) --- 整体架构- 罗西的思考- 博客园

Multi-Node Multi-Card Training Using DistributedDataParallel_ModelArts_Model Development_Distributed Training
apex/apex/parallel/distributed.py at master · NVIDIA/apex · GitHub

torch.nn、(一)_51CTO博客_torch.nn

Distributed PyTorch Modelling, Model Optimization, and Deployment